WARNING This assignment can generate reams of output. Edit your *.lst files to remove useless stuff before printing them!
Introduction
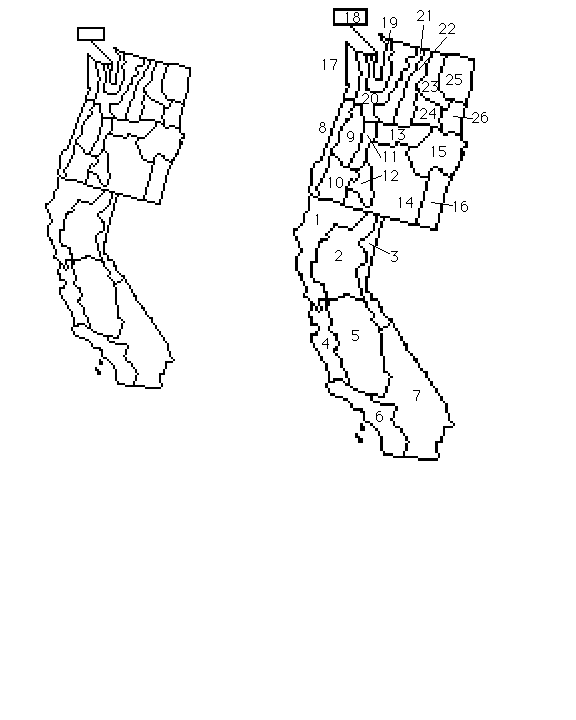
The data set westcoast.sas contains 50 year long time series of monthly precipitation (600 obs total) for 26 climate divisions located along the conterminous United States west coast. A "climate division" is a (usually small) area comprising one or more meteorological stations. These data, which span the period from January, 1948 to December, 1997, inclusive, were originally obtained from the National Climatic Data Center (NCDC) data archive. Here is an ugly but usable base map for the west coast climate divisions.
The data matrix X is 600 (months) by 26 (objects). We will perform object-based PCA, spectral and cluster analyses on these data. First, however, each object will be standardized to zero mean and unit variance. Thus, our PCA will be on the object correlation matrix. I am intentionally removing mean and variance differences among the objects, leaving the phasing of the objects' temporal fluctuations as their sole source of distinctiveness. The intent here is to create "component objects" or object clusters that emphasize raw temporal similarity.
What is to be done
We will do the following: (1) Unrotated PCA, with spectral analysis of the component time series; (2) Rotated PCA, as a form of cluster analysis; (3) Traditional geometric cluster analysis, for comparison and contrast with PCA-based clustering.
Periodogram spectral analysis
Here is a brief explanation (I'll have a handout
on this topic). This technique, which distributes the adjusted TSS of a time series
among a variety of periods, is actually closely related to linear
regression. Suppose you have a time series of M (here, 600) data points, spanning
temporal length T (here, 600
months) with a time resolution of DT (here, 1 month). The series is
centered to zero mean.
You examine the "spectral power" at a set of periodicities
related to the total time series length: T, T/2, T/3,... down to 2DT, for a
total of M/2 periods. For a given period,
you fit the OLS model of Y = Beta1*cos(period) +
Beta2*sin(period) + error, where Y is the component time series you're analyzing.
The SSR of this regression is the series' spectral power at the chosen period.
At this point, it sounds like we'd have to do M/2 separate regressions and, more importantly, worry about redundancy and partial correlations. Not so. Keep in mind that a sine and cosine of the same period are uncorrelated. Further, a sine (or cosine) of any period is uncorrelated with sines and cosines of all other periods. Thus, we can build an OLS model combining all M completely independent terms (M/2 sines and M/2 cosines, spanning M/2 different periods) without worrying about colinearities, inflated standard errors, biased estimates or overlapping SSRs. Because each regressor is completely independent, there is no overlap and the sum of the individual SSRs of each period equals the adjusted TSS for the time series Y.
Geometric cluster analysis
This will also be gone over in much more detail in class. Traditional
cluster analysis starts with a "dissimilarity matrix" for the N
objects, a square, symmetric NxN matrix comprising the geometric distances between
all possible object pairs. "Agglomerative hierarchical" cluster analysis
starts with N clusters (one object per cluster) and in each step
identifies and fuses the cluster pair with the smallest geometric separation.
Once a cluster fusion takes place, the distance between the new, multiobject
cluster
and all remaining clusters has to be recomputed. Clustering algorithms
vary dramatically on how this is accomplished.
In each step of agglomerative hierarchical clustering, the number of remaining clusters is reduced by one, and clustering terminates when one, all-inclusive cluster is forged. Then, the results are inspected and one or more clustering levels are selected. There are tests and rules for choosing among the N possible clustering levels. Generally, they aren't very good tests. Most algorithms make "hard" clusters; each object belongs to one, and only one, cluster. This is often unreasonable; real clusters should be "fuzzy" (overlapping).
List of specific tasks, with detailed notes
Notes
Tasks
Notes
Tasks
Notes
Task
SAS code from westcoast.sas
* ------------------------------------------------------------------------;
* preliminary data manipulation;
* ------------------------------------------------------------------------;
* the data set starts out divisions (objects) x months (obs/vars) 26x600;
* here we transpose the data set to make it months x divisions or 600x26;
* the objects are now called col1-col26;
proc transpose data=precip out=trans;
* now standardize the objects to zero mean, variance one
(we can make FACTOR do this... just making it obvious it was done);
proc standard m=0 s=1 data=trans out=stand; var col1-col26;
* ------------------------------------------------------------------------;
* (1) PCA on the objects -- do an unrotated analysis first;
* ------------------------------------------------------------------------;
* proc factor does the PCA on the 26x26 correlation matrix for the objects,
and reports the V eigenvalue-scaled eigenvectors;
proc factor data=stand rotate=NONE score outstat=factout1; var col1-col26;
* proc score creates the standardized Y scores (called factorN,
where N is the root number), the 600x26 replacement data matrix;
* the Y score data set contains time series for the component objects;
proc score data=stand score=factout1 out=score1; var col1-col26;
* if score worked correctly, the new component data set should be
uncorrelated -- check for first 5 factors (we are such skeptics);
proc corr data=score1; var factor1-factor3;
* send a few of the component time series to proc spectra for
periodogram spectral analysis;
* the data set "specout" contains spectral power ("P_*") for each
included period, which is in months (600 months is max period);
proc spectra p adjmean data=score1 out=specout; var factor1-factor3;
proc print data=specout;
* ------------------------------------------------------------------------;
* (2) now do a rotated PCA on the objects;
* ------------------------------------------------------------------------;
* here, we truncate the PCA, keeping only the roots with eigenvalues
greater than one, and then perform a Varimax rotation;
* check out the rotated "factor" (eigenvector) loadings and perform
a PCA-based fuzzy clustering;
proc factor data=stand rotate=varimax; var col1-col26;
* what happens if we had NOT truncated - would the clustering have
been different? Check it out;
proc factor data=stand N=26 score outstat=factoutr rotate=varimax; var col1-col2
6;
* ------------------------------------------------------------------------;
* (3) A traditional Euclidean-based cluster analysis;
* ------------------------------------------------------------------------;
* first, get the standardized data set back to divisions x months;
* now the months/obs will be called obs1-obs600;
proc transpose data=stand out=tempor;
* we need a division identifier, so make one using data command;
data precips; set tempor;
id=_N_;
* do an average linkage cluster analysis, requesting "pseudo" statistics;
* our cluster routine computes a 26x26 Euclidean distance matrix from the
standardized 26x600 data set;
proc cluster data=precips method=average pseudo outtree=tree; var obs1-obs600;
id id;
* proc tree processes the output from cluster and prints large useless
diagram if NOPRINT is not specified;
* the number of clusters is specified in nclusters option;
proc tree data=tree noprint out=output nclusters=3; id id;
* sorting the output from tree for easy presentation;
proc sort data=output; by cluster id;
* print it out;
proc print uniform; id id;
* ------------------------------------------------------------------------;
* extra material after this line - remove asterisks to enable proc calls;
* ------------------------------------------------------------------------;
* above, we did a cluster analysis on the 26x600 standardized data set;
* we also could have performed the cluster analysis on the 26x26 V eigenvectors
from proc factor... even after rotation... that's the same information
so long as we don't __truncate__;
* to prove that we take the output data set from the untruncated, varimax rotated
PCA on the objects above, extract the 26x26 eigenvector loading matrix
(SAS datatype 'PATTERN'), transpose it in preparation for input to cluster;
* in the first cluster proc, we computed a Euclidean distance (ED) matrix
from a 600x26 data set. In the second we computed the ED matrix from a
26x26 data set. But it told us the very same thing;
* proc score data=stand score=factoutr out=scorer;
* var col1-col26;
* data fact1;
* set factoutr;
* if _type_='PATTERN';
* proc transpose data=fact1 out=fact2;
* proc print;
* proc cluster data=fact2 method=average pseudo outtree=tree1;
* var factor1-factor26;
{kind=link}